DIM, is a portable, light weigth, package for information publishing, data transfer and inter-process communications. Like most communication systems, is based on the client/server paradigm.
The basic concept in the DIM approach is the concept of "service". Servers provide services to clients. A service is normally a set of data (of any type or size) and it is recognized by a name - "named services". The name space for services is free.
Services are normally requested by the client only once (at startup) and they are subsequently automatically updated by the server either at regular time intervals or whenever the conditions change (according to the type of service requested by the client).
The client updating mechanism can be of two types, either by executing a callback routine or by updating a client buffer with the new set of data, or both. In fact this last type works as if the clients maintain a copy of the server's data in cache, the cache coherence being assured by the server.
In order to allow for transparency (i.e, a client does not need to know where a server is running) as well as to allow for easy recovery from crashes and migration of servers, a name server was introduced.
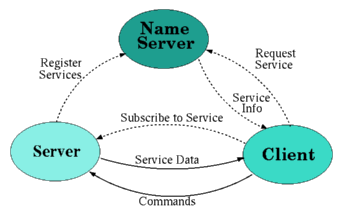
Servers "publish" their services by registering them with the name server (normally once, at startup).
Clients "subscribe" to services by asking the name server which server provides the service and then contacting the server directly, providing the type of service and the type of update as parameters.
The name server keeps an up-to-date directory of all the servers and services available in the system. The Figure shows how DIM components (Servers, Clients and the Name Server) interact.
Whenever one of the processes (a server or even the name server) in
the system crashes or dies all processes connected to it will be notified
and will reconnect as soon as it comes back to life. This feature not only
allows for an easy recovery, it also allows for the easy migration of a
server from one machine to another (by stopping it in the first machine
and starting it in the second one), and so for the possibility of
balancing
the machine load of the different workstations.